
C语言11-结构体
1. 基本知识
1.1 概念
结构体属于用户自定义的数据类型,允许用户存储不同的数据类型
由一批数据组合而成的结构型数据
1.2 定义和使用
定义方法:
1 | struct 结构体名 |
通过结构体创建变量的方式有三种:
- struct 结构体名 变量名
- struct 结构体名 变量名 = { 成员1值 , 成员2值…}
- 定义结构体时顺便创建变量
示例:
1 | //结构体定义 |
注意:结构体书写位置不同会有不同的生效域:书写在函数里面是局部位置,只能在本函数中使用;书写在函数外面是全局位置,在所有的函数中都能使用。
给结构体变量赋值:变量名.属性 = 值;
1 | stu3.name = "王五"; |
2. 结构体数组
作用:将自定义的结构体放入到数组中方便维护
语法: struct 结构体名 数组名[元素个数] = { {} , {} , ... {} };
struct 结构体名 数组名[元素个数] = { 变量1 , 变量2, ... 变量n };
示例:
1 | struct student |
3. 起别名
作用:简化使用结构体名时的繁琐
语法:在定义前加typedef
1 | typedef struct 结构体名 |
其中的结构体名可以省略
4.结构体作为函数的参数进行传递
作用:将结构体作为参数向函数中传递
示例:(修改学生名字)
1 | //学生结构体定义 |
5. 结构体嵌套
作用: 结构体中的成员可以是另一个结构体
示例:
1 | struct Message{ |
6.结构体内存对齐
确定变量位置:只能放在自己类型的整数倍的内存地址上
最后一个补位:结构体的总大小,是最大类型的整数倍
1 | struct num{ |
占内存应该如下(空的地方会填充空字节直到24,因为24是8的整数倍):
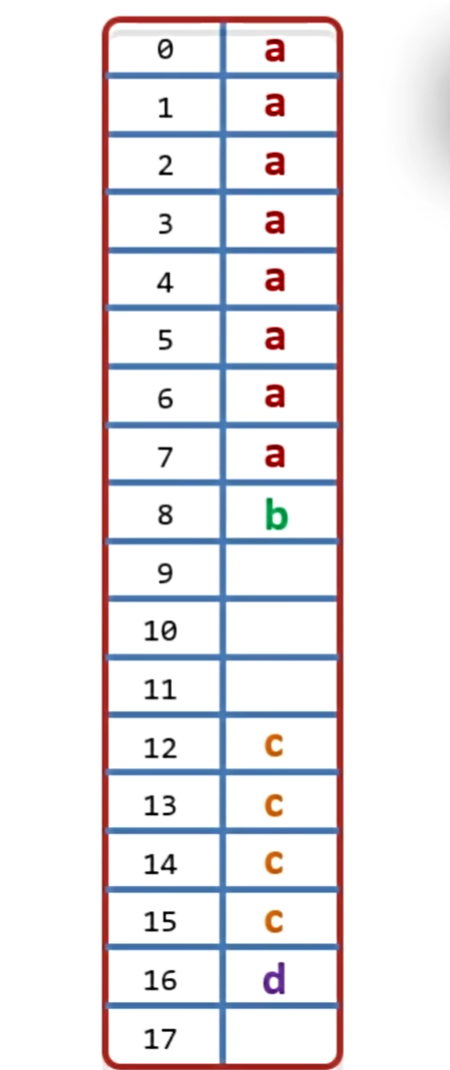
- 内存对齐:不管是结构体还是普通变量都存在的规则,只能放在自己类型整数倍的内存地址上(内存地址/占用字节 = 结果可以整除);
总结:把小的数据类型写在最上面,大的数据类型写在最下面可以节约空间
7. 补充知识
7.1 结构体成员是指针
- 定义包含指针的结构体
1 | struct Person { |
在这个结构体中,name 是一个指针,它指向字符数组(字符串)的起始位置,而 age 是一个普通的整数类型。
- 动态分配内存给指针成员
因为 name 是一个指针,通常我们需要为它动态分配内存,这样才能存储名字。可以使用 malloc 函数来为指针分配内存。
1 | struct Person p1; |
- 访问结构体中的指针成员
- 如果你直接使用结构体变量访问指针成员,可以使用
.操作符:
1 | p1.name = "Alice"; // 直接给指针赋值一个字符串字面值 |
- 如果你使用指向结构体的指针来访问结构体的成员,使用
->操作符:
1 | struct Person *p_ptr = &p1; |
7.2 链表
7.1 基本概念
链表是一种线性数据结构,由一系列节点组成。每个节点包含两部分:
- 数据部分(Data):用于存储节点的数据。
- 指针部分(Pointer):存储下一个节点的地址,用于链接下一个节点。
链表的首节点通常称为头节点(Head),而最后一个节点指向NULL,表示链表的结束。
7.2 分类
7.2.1 单向链表(Singly Linked List)
每个节点只有一个指向下一个节点的指针。链表的最后一个节点指向NULL。
1 | struct Node { |
7.2.2 双向链表(Doubly Linked List)
每个节点有两个指针,一个指向前一个节点,另一个指向后一个节点。这样可以从链表的任意节点进行前向和后向遍历。
1 | struct Node { |
7.2.3 循环链表(Circular Linked List)
循环链表的特点是链表的最后一个节点指向链表的头节点,这样链表可以像一个环一样循环遍历。可以是单向或双向的。
1 | struct Node { |
7.3 链表的操作
链表中的常见操作包括节点的插入、删除、遍历和查找。
插入操作
- 在链表头部插入:将新节点插入到头节点之前,并将头指针更新为新节点。
- 在链表尾部插入:遍历到链表末尾,将新节点插入到尾节点之后。
- 在链表中间插入:找到目标位置的前一个节点,并将新节点插入该位置。
头部插入的代码示例:
1 | void insertAtHead(struct Node** head, int newData) { |
删除操作
- 删除头节点:直接将头节点的指针指向下一个节点,然后释放原头节点的内存。
- 删除尾节点:需要遍历到倒数第二个节点,将其指向
NULL,并释放原尾节点。 - 删除中间节点:找到要删除节点的前一个节点,调整指针并释放要删除的节点。
删除头节点的代码示例:
1 | void deleteAtHead(struct Node** head) { |
注意一定要释放掉被删除的节点,不然会产生野指针,野指针的出现会造成严重的内存泄漏
遍历链表
从头节点开始,逐个访问节点的数据,直到NULL节点为止。
遍历链表的代码示例:
1 | void printList(struct Node* head) { |
查找操作
遍历链表,查找与目标值匹配的节点。
查找操作的代码示例:
1 | struct Node* search(struct Node* head, int target) { |
7.4 链表的内存管理
在C语言中,链表的节点是动态分配的内存,因此需要合理使用malloc进行内存分配,并使用free释放节点不再使用时的内存,防止内存泄漏。
1 | struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); |
释放节点的内存:
1 | free(node); |

