1. 顺序表 1.1 概念 线性表(Linear List): 由同类型数据元素构成有序序列的线性结构
表中元素个数称为线性表的长度
线性表没有元素时,称为空表
表起始位置称表头,表结束位置称表尾
线性表的结构: 一段连续的存储空间、两个属性:size(表的大小),count(元素个数)
1.2 代码实现 1.2.1 结构定义 1 2 3 4 typedef struct vector { int size, count; int * data; }vector ;
1.2.2 初始化(创建)新表 1 2 3 4 5 6 7 vector * getNewVector (int n) { vector * p = (vector *)malloc (sizeof (vector )); p->size = n; p->count = 0 ; p->data = (int *)malloc (sizeof (int ) * n); return p; }
1.2.3 销毁顺序表 1 2 3 4 5 void clear (vector * v) { if (v == NULL ) return ; free (v->data); free (v); return ;
1.2.4 插入新元素 1 2 3 4 5 6 7 8 9 10 int insertVector (vector * v, int pos, int val) { if (pos < 0 || pos > v->count) return 0 ; if (v->size == v->count && !expand(v)) return 0 ; for (int i = v->count - 1 ; i >= pos; i--) { v->data[i + 1 ] = v->data[i + 1 ]; } v->data[pos] = val; v->count += 1 ; return 1 ; }
1.2.5 删除元素 1 2 3 4 5 6 7 8 int eraseVector (vector * v, int pos) { if (pos < 0 || pos >= v->count) return 0 ; for (int i = pos + 1 ;i < v->count;i++) { v->data[i - 1 ] = v->data[i]; } v->count -= 1 ; return 1 ; }
1.2.x 输出顺序表 1 2 3 4 5 6 7 8 9 10 11 12 void outputVector (vector *v) { int len = 0 ; for (int i = 0 ;i < v->size;i++) { len += printf ("%3d" , i); } printf ("\n" ); for (int i = 0 ; i < len;i++) printf ("-" ); printf ("\n" ); for (int i = 0 ;i < v->count;i++) { printf ("%5d" , v->data[i]); } }
1.2.6 扩容操作 1 2 3 4 5 6 7 8 int expand (vector * v) { if (v == NULL ) return 0 ; int *p = (int *)realloc (v->data, sizeof (int ) * 2 * v->size); if (p == NULL ) return 0 ; v->data = p; v->size *= 2 ; return 1 ; }
2. 链表 2.1 概念 链表是一种动态的数据结构,由一系列节点组成
每个节点包含两部分:数据域(存储实际数据)和指针域(指向下一个节点)
2.2 代码实现 2.2.1 结构定义 1 2 3 4 typedef struct Node { int data; struct Node * next ; }Node;
2.2.2 初始化(创建)链表节点 1 2 3 4 5 6 Node* getNewNode (int val) { Node* p = (Node *)malloc (sizeof (Node)); p->data = val; p->next = NULL ; return p; }
2.2.3 销毁整段链表 1 2 3 4 5 6 7 void clearNode (Node* head) { if (head == NULL ) return ; for (Node* p = head, *q; p; p = q) { q = p->next; free (p); } }
2.2.4 插入链表节点 1 2 3 4 5 6 7 8 9 10 11 12 13 Node* insert (Node* head, int pos, int val) { if (pos == 0 ) { Node* p = getNewNode(val); p->next = head; return p; } Node* p = head; for (int i = 1 ; i < pos; i++) p = p->next; Node* node = getNewNode(val); node->next = p->next; p->next = node; return head; }
1 2 3 4 5 6 7 8 9 10 Node* insert (Node* head, int pos, int val) { Node new_head, * p = &new_head; new_head.next = head; Node* node = getNewNode(val); for (int i = 0 ; i < pos; i++) p = p->next; node->next = p->next; p->next = node; return new_head.next; }
2.2.5 删除链表节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Node* deleteNode (Node* head, int pos) { if (head == NULL ) return ; if (pos == 0 ) { Node* temp = head->next; free (head); return temp; } Node* p = head; for (int i = 1 ; i < pos && p != NULL ; i++) { p = p->next; } if (p == NULL || p->next == NULL ) { return head; } Node* temp = p->next; p->next = temp->next; free (temp); return head; }
2.2.6 查找 1 2 3 4 5 6 7 8 int find1 (Node* head, int val) { Node* p = head; while (p) { if (p->data == val) return 1 ; p = p->next; } return 0 ; }
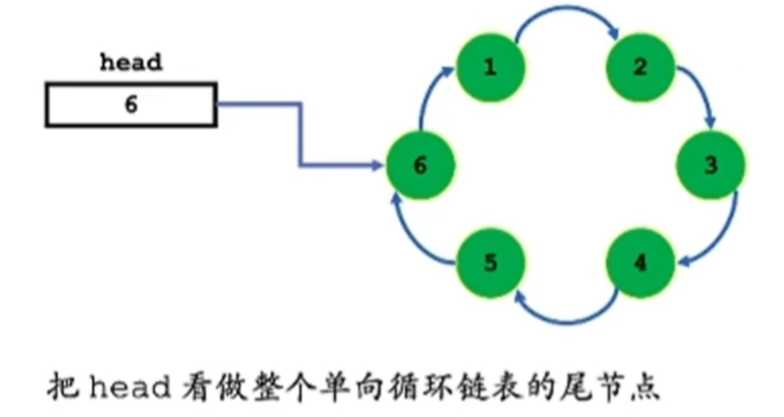
2.3 其他链表 2.3.1 循环链表 2.3.2 双向链表
3. 队列 3.1 概念 队列 是具有一定操作约束的线性表
插入和删除操作:只能在一端插入,而在另一端删除
数据插入:入队列 (AddQ)
数据删除:出队列(DeleteQ)
先来先服务,先进先出(FIFO)
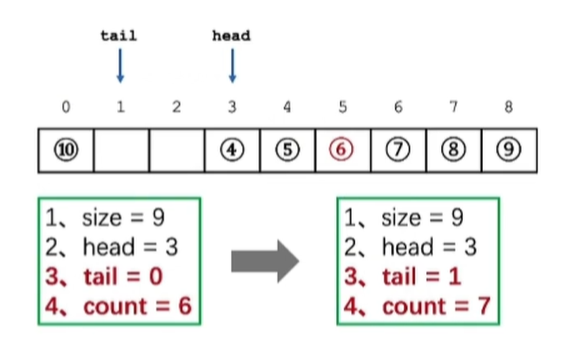
循环队列: 更好有效利用空间
3.2 代码实现-顺序表
以下假定已经创建了顺序表
3.2.1 结构定义 1 2 3 4 typedef struct Queue { vector * data; int size, head, tail, count; }Queue;
3.2.2 初始化 1 2 3 4 5 6 7 Queue* initQueue (int n) { Queue* q = (Queue*)malloc (sizeof (Queue)); q->data = initVector(n); q->size = n; q->head = q->tail = q->count = 0 ; return q; }
3.2.3 清除队列 1 2 3 4 5 6 void clearQueue (Queue *q) { if (q == NULL ) return ; clearVector(q->data); free (q); return ; }
3.2.4 入队 1 2 3 4 5 6 7 8 int push (Queue* q, int val) { if (q->count == q->size) return 0 ; insertVector(q->data, q->tail, val); q->tail += 1 ; if (q->tail == q->size) q->tail = 0 ; q->count += 1 ; return 1 ; }
3.2.5 出队 1 2 3 4 5 6 int pop (Queue* q) { if (isEmpty(q)) return 0 ; q->head += 1 ; q->count -= 1 ; return 1 ; }
3.2.x 队列判空 1 2 3 int isEmpty (Queue* q) { return q->count == 0 ; }
3.2.x 查看队首元素 1 2 3 int front (Queue* q) { return vectorSeek(q->data, q->head); }
3.3 代码实现-链表 3.3.1 结构定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef struct Queue { Node* l; int size, count; }Queue; typedef struct Node { int data; Node* next; }Node; typedef struct LinkList { Node head; Node* tail; }LinkList;
3.3.2 初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 LinkList *initLinklist () { Linklist* l = (Linklist *)malloc (sizeof (LinkList)); l->head.next = NULL ; l->tail = &(l->head); return l; } Queue* initQueue () { Queue* q = (Queue*)malloc (sizeof (Queue)); q->l = initLinkList(); q->count = 0 ; return q; }
3.3.3 清除队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void clearLinkList (LinkList *l) { Node *p = l->head.next, *q; while (p){ q = p->next; free (p); p = q; } free (l); return ; } void clearQueue (Queue* q) { if (q == NULL ) return ; clearLinkList(q->l); free (q); return ; }
3.3.4 入队 1 2 3 4 5 6 7 8 9 10 11 insertTail(LinkList *l, int val) { LinkList *node = getNewNode(val); l->tail->next = node; l->tail = node; return 1 ; } int push (Queue* q, int val) { insertTail(q->l, val); return 1 ; }
3.3.5 出队 1 2 3 4 5 6 7 8 9 10 11 12 13 int eraseHead (LinkList *l) { if (emptyList(l)) return 0 ; Node* p = l->head.next; l->head->next = l->head.next->next; if (p == l->tail) l->tail = &(l->head); free (p); return 1 ; } int pop (Queue* q) { eraseHead(q->l); return 1 ; }
4. 栈 4.1 概念 堆栈(Stack)是一种常见的数据结构 ,它具有后进先出 (Last In, First Out,LIFO)的特性。意思是,最后存入堆栈的数据最先被取出。
只在一端(栈顶,Top)做插入、删除
插入数据:入栈/压栈 (Push)
删除数据:出栈/弹栈 (Pop)
4.2 代码实现-数组顺序表 4.2.1 结构定义 1 2 3 4 typedef struct Stack { int * data; int size, top; }Stack;
4.2.2 初始化 1 2 3 4 5 6 7 Stack* initStack (int n) { Stack* s = (Stack*)malloc (sizeof (Stack)); s->data = (int *)malloc (sizeof (int ) * n); s->size = n; s->top = -1 ; return s; }
4.2.3 清除栈 1 2 3 4 5 6 void clearStack (Stack* s) { if (s == NULL ) return ; free (s->data); free (s); return ; }
4.2.4 入栈 1 2 3 4 5 6 int push (Stack* s, int val) { if (s->top + 1 == s->size) return 0 ; s->top += 1 ; s->data[s->top] = val; return 1 ; }
4.2.5 出栈 1 2 3 4 5 int pop (Stack* s) { if (empty(s)) return 0 ; s->top -= 1 ; return 1 ; }
4.2.x 判空和查看栈顶元素 1 2 3 4 5 6 7 8 int (empty(Stack* s)) { return s->top == -1 ; } int top (Stack* s) { if (empty(s)) return 0 ; return s->data[s->top]; }
4.3 栈的深入理解 4.3.1 引入:括号序列问题 给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
题解: 典型的栈题(解法略),可以+1抽象为进,-1抽象为出
思维提升:
4.3.2 总结:栈更高维地处理问题 栈可以处理具有完全包含 关系的问题